Phylogeny-based Protein Function Prediction
SIFTER (Statistical Inference of Function Through Evolutionary Relationships) is a statistical approach to predicting protein function that uses a protein family's phylogenetic tree, as the natural structure for representing protein relationships.
Help with SIFTER web server
Quick Search
Welcome to the SIFTER web server. The home page provides a quick search option, where you can search for SIFTER predictions for a protein, species, or molecular function. You can enter a Uniprot ID, Uniprot accession number, species name, tax ID, GO term ID, or molecular function name.
We provide suggestions of queries as you are typing. In the example below, we provide the closest searches to the user's query "sulfate". Clicking on any of the suggestions will automatically search for that query.
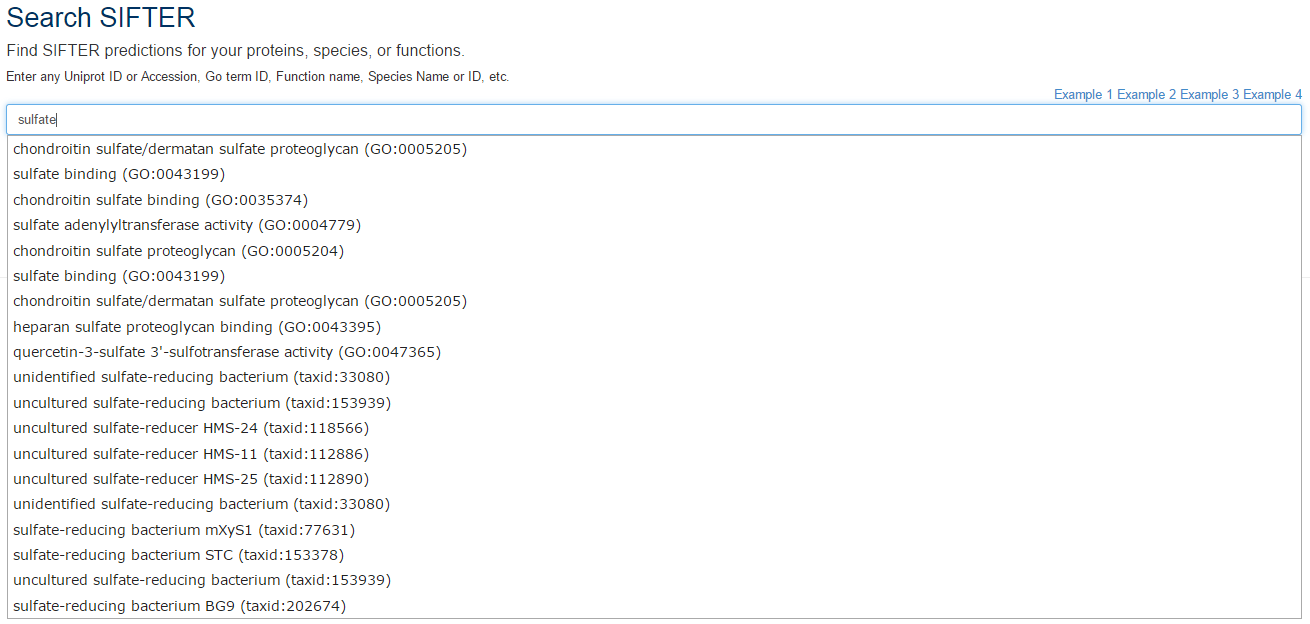
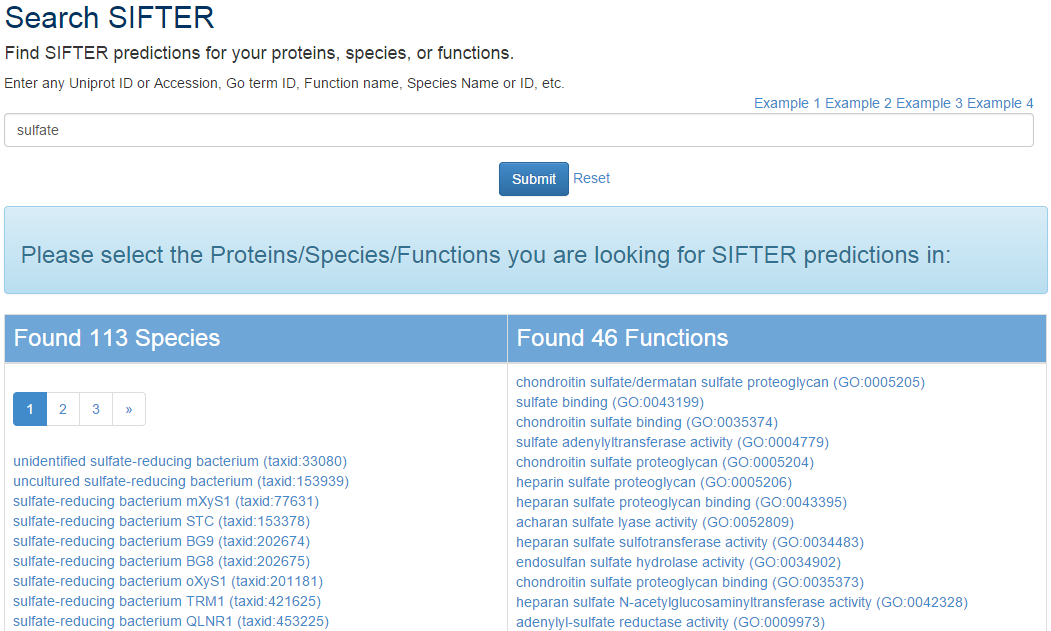
If your query matches multiple proteins, species, or functions in our database, we provide a list of all matches so that you can select the protein, species, or function that you are looking for.
You can click on one of the four examples to see examples of queries. Here we show a search for the protein with Uniprot accession number PA24B_MOUSE.
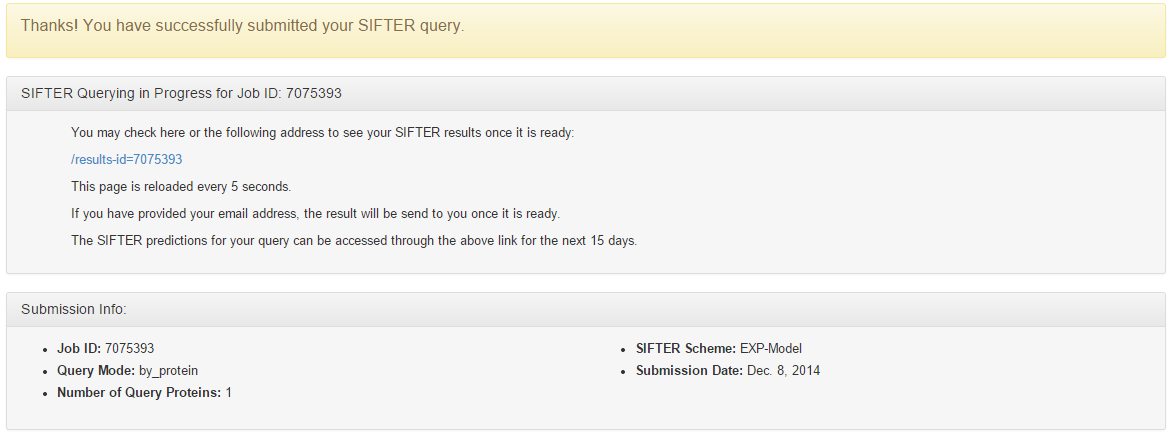
When you press submit, you should see the following screen, which provides the details of the search and a Job ID.
If you save the Job ID, you can come back later and retrieve the results when SIFTER finishes processing the query. The results will be stored on the provided link for 15 days.
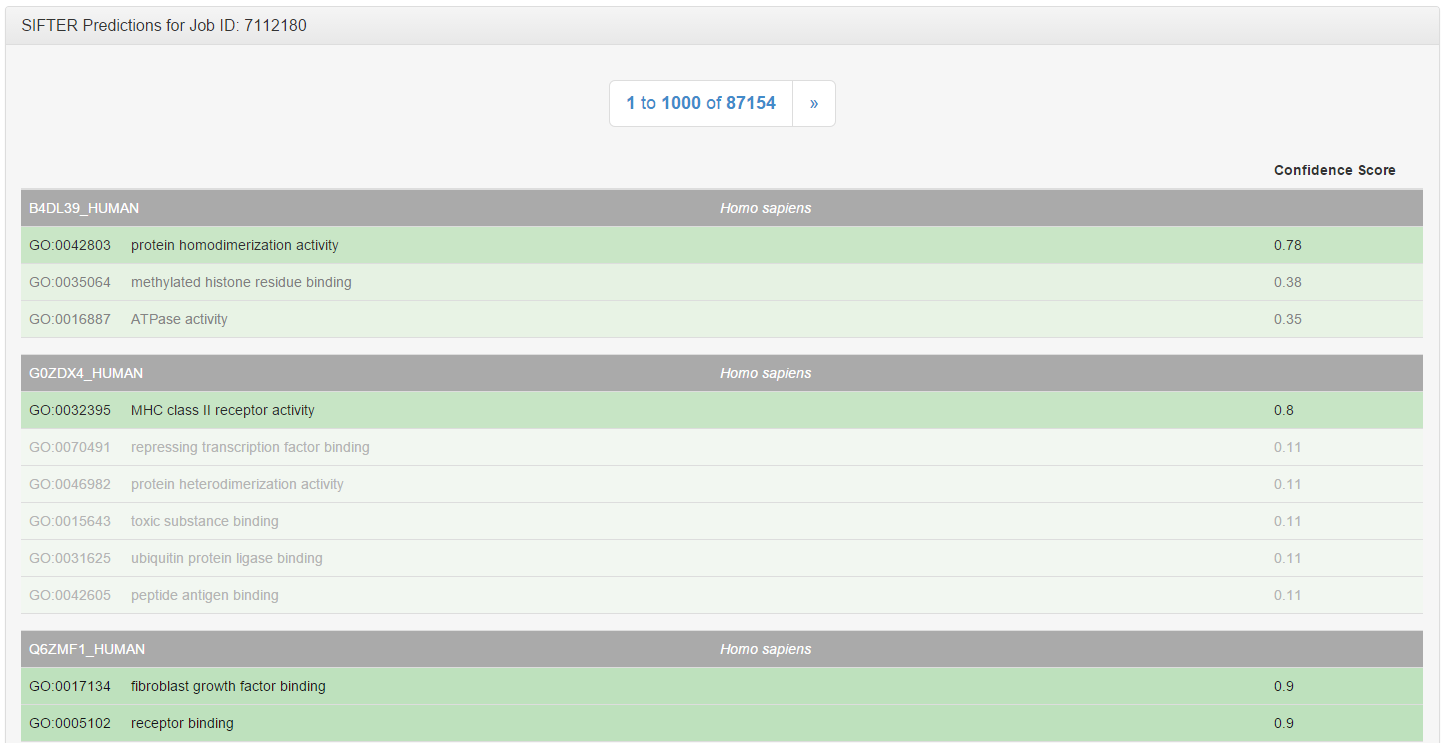
Here are the results from the example query. For each protein, we display a table of the molecular functions (GO term ID and name) with the highest confidence scores for that protein. Each molecular function links to a corresponding search in the AmiGO database.
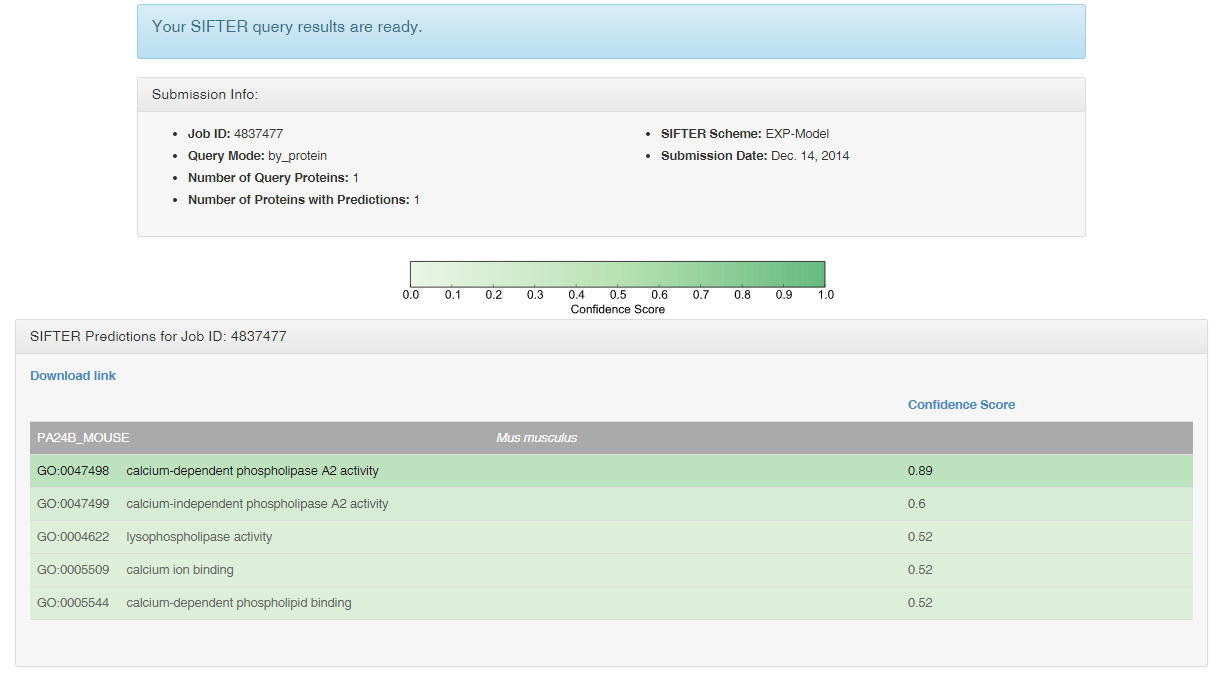
In this example, the protein PA24B_MOUSE in the species M. musculus has a confidence score of 0.89 for the molecular function "calcium-dependent phospholipase A2 activity" (GO: 0047498).
You can also download the results as the text format using the provided download link.
Our quick search is a general search that handles proteins, species, or functions. For searches more specific to the type of your query, check out the "Advanced Search" section.
The confidence score is a number between 0 and 1 that shows how confident SIFTER is on the prediction results. It is defined based on the number of candidate functions, the family size, and the frequency and distribution of candidate terms in the tree. Click here to learn more.
Advanced Search
There are four types of advanced search: predict by protein, predict for all proteins of a species, find proteins that have given functions, and predict for homologs of given Sequences.
For all advanced searches, you can choose between two SIFTER schemes for incorporating existing annotations. SIFTER EXP-Model, the default option, only uses experimental evidence, whereas SIFTER ALL-Model includes both experimental and non-experimental evidence.

Just click on "Show advanced options" to choose a scheme.
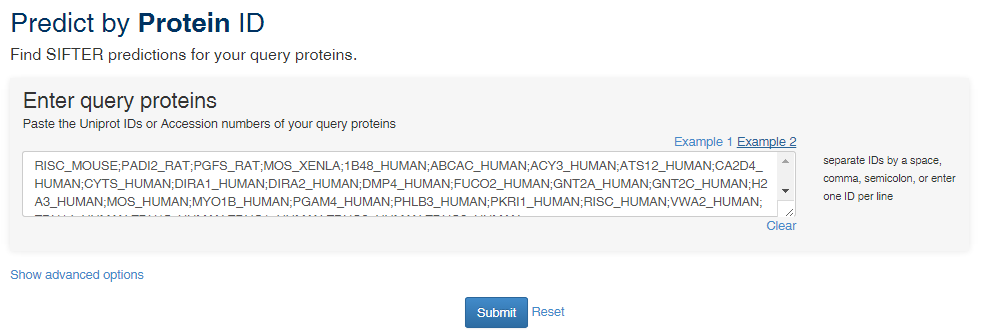
Predict by Protein ID
"Predict by Protein ID" retrieves the SIFTER predictions for your protein or proteins of interest.
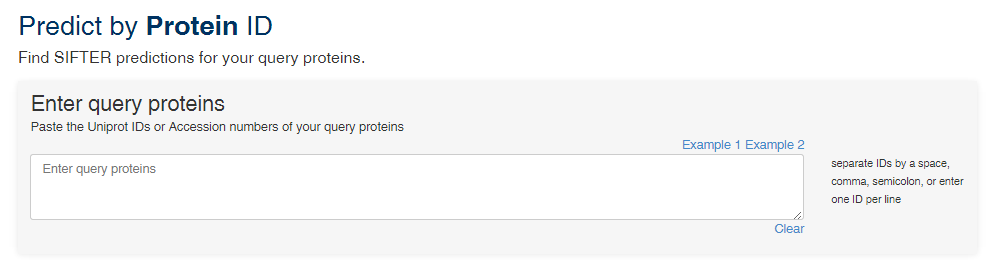
You can enter a single protein Uniprot ID or accession number, or you can provide a list of proteins separated by commas. In the example below, we search for a list of 29 Uniprot accession numbers.
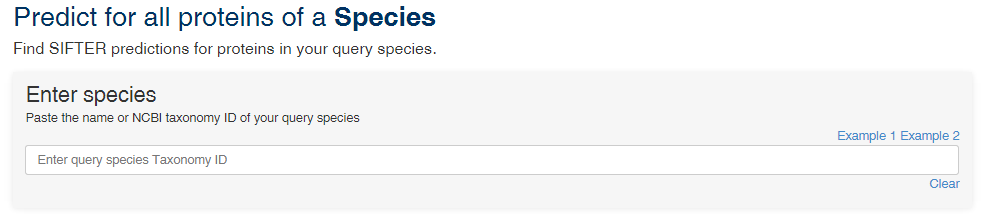
Predict for all proteins of a Species
"Predict for all proteins of a Species" retrieves the SIFTER predictions on all proteins in your species of interest.
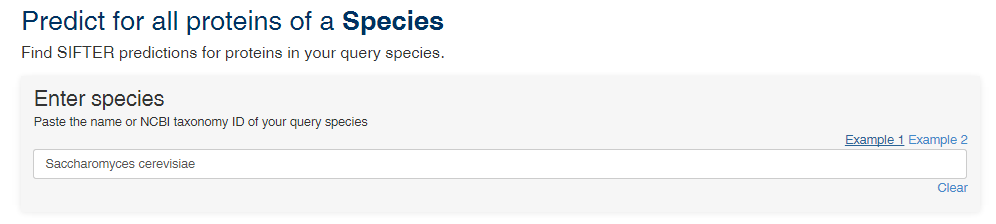
You can enter the name or the tax ID of your species. Here we search for predictions on all of the proteins in the species S. cerevisiae.
Here are the SIFTER predictions for proteins in Homo sapiens (tax ID 9606).
Find proteins that have given Functions
"Find proteins that have given Functions" retrieves the SIFTER predictions on all proteins in your species of interest with at least one of the specified molecular functions of interest or their descendants as the top predicted functions.
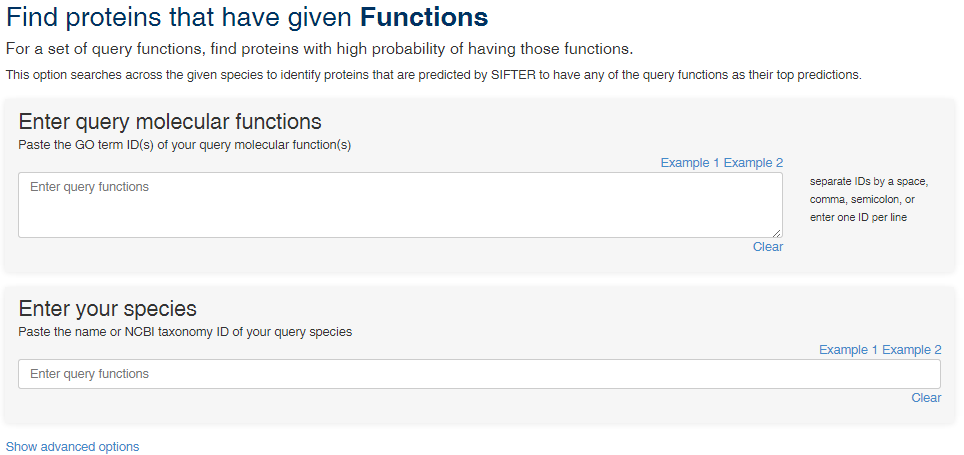
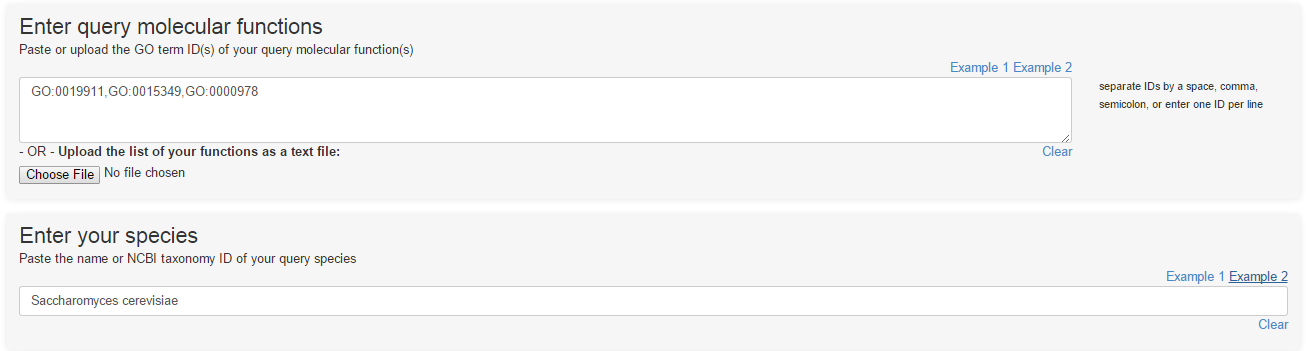
As in "Predict by Protein ID", you can specify a single GO term ID, or a list of comma-separated GO term IDs. In the species section, you can enter the name or the tax ID of your species of interest. For example, you can search for proteins in S. cerevisiae that have one or more of the functions GO:0019911, GO:0004657, or GO:0050660 or any of their descendants.
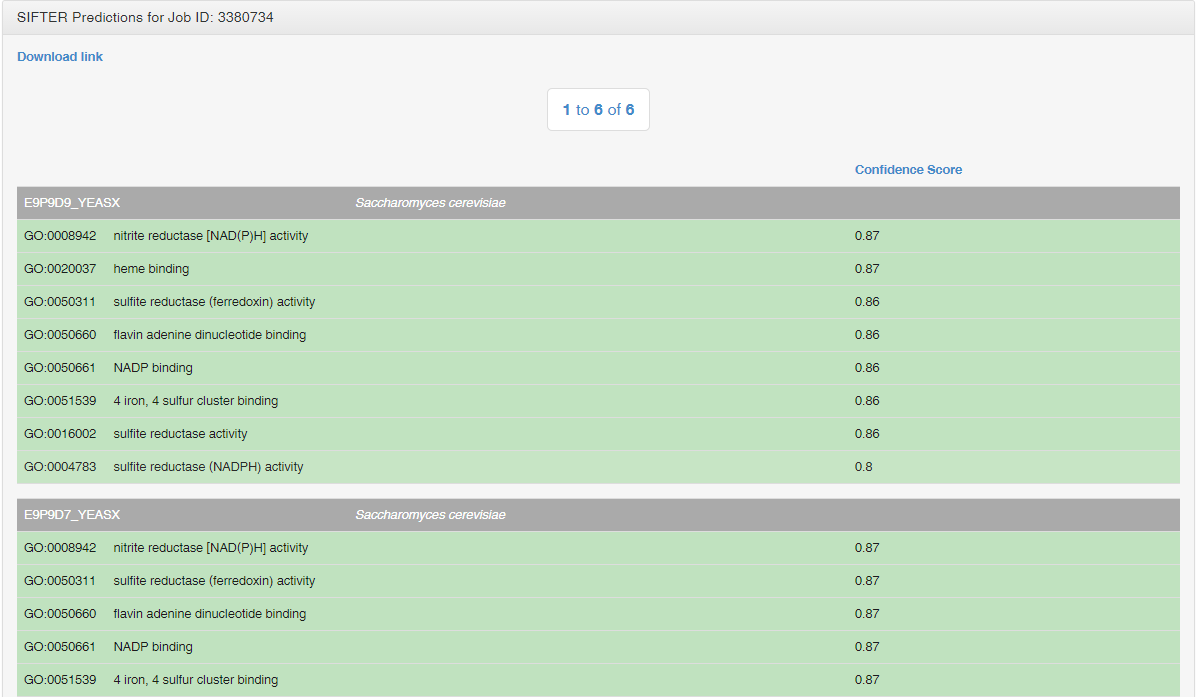
Here are the SIFTER predictions for that search.
Predict for homologs of given Sequences
If your query does not match any of our current results, check out "Predict for homologs of given Sequences". We will BLAST search your query protein sequence(s) across all proteins for which SIFTER has predictions to find the closest homologs to your query sequence(s).
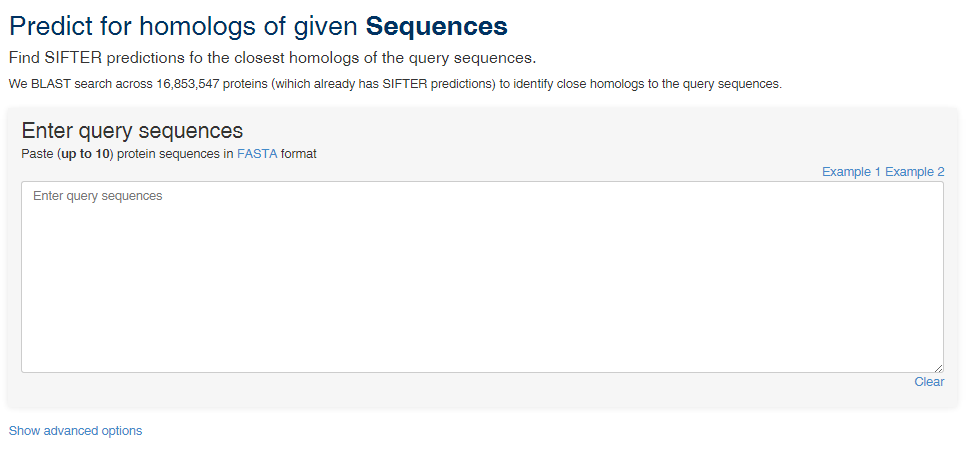
To predict by sequence, you can enter up to 10 protein sequences in FASTA format or upload a FASTA format file. Here is an example query with two protein sequences in FASTA format.
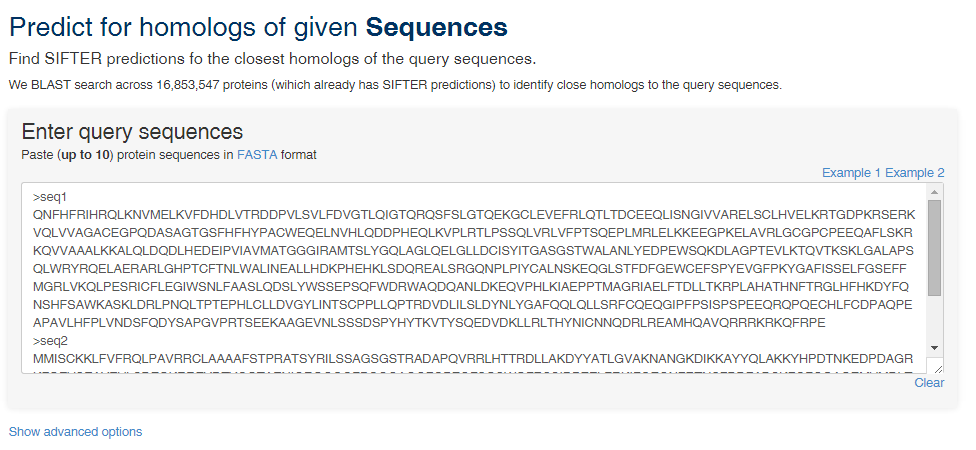
In the results page, we indicate the number of proteins in our database that are homologous to your query sequence(s) along with the SIFTER predictions for them.
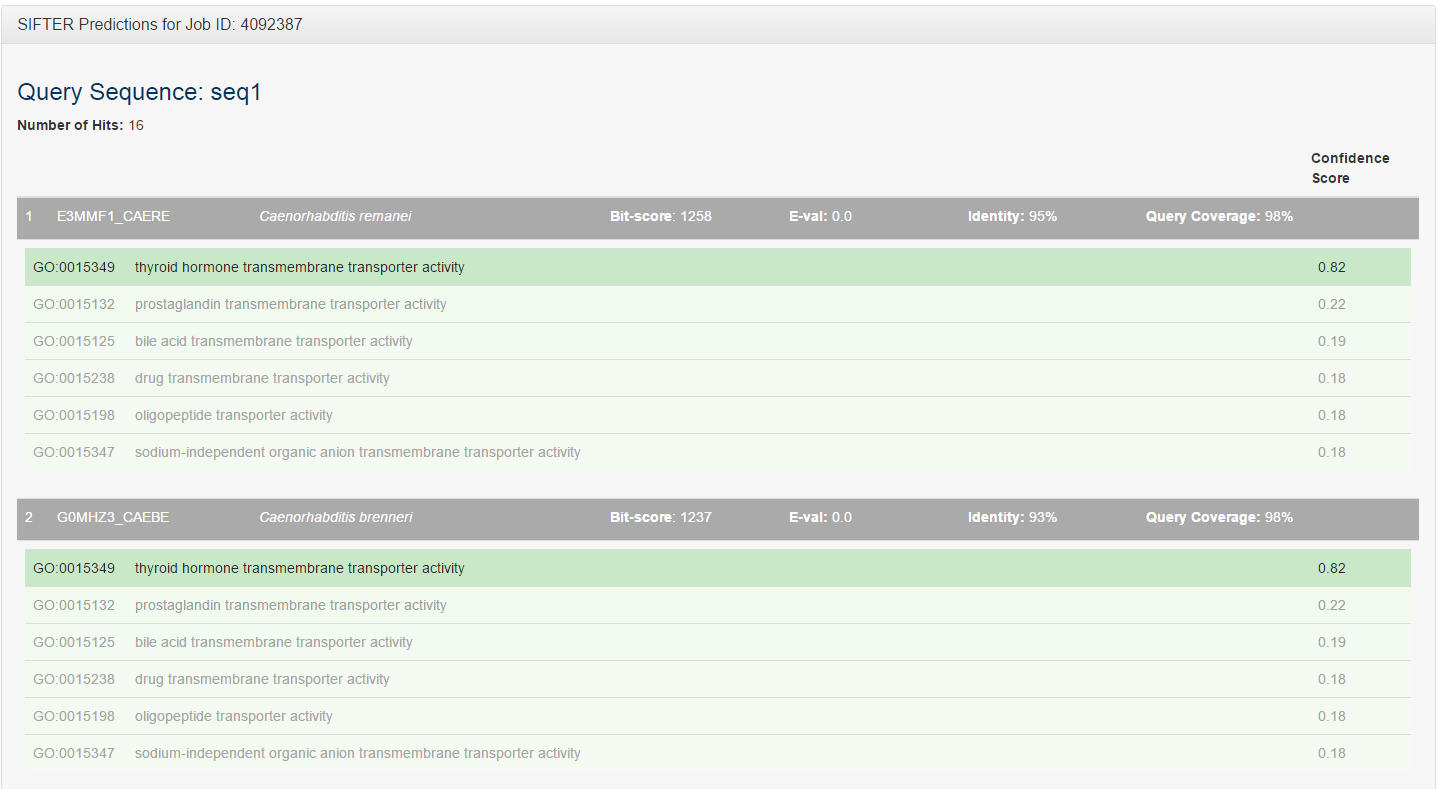
For each homologous protein, we also report the BLAST specific results: the bit score, E-value, percent identity, and query coverage.
Run SIFTER locally
If you have downloaded SIFTER and want to know how long it will run on your protein family of interest, check out the second link in the download tab.
Since the processing time complexity of SIFTER is exponential in the number of candidate molecular functions, SIFTER provides the truncation level as an additional parameter to set the maximum number of molecular functions any protein is assigned. This significantly reduces the time complexity of SIFTER with minimal impact on the prediction results. In order to select the truncation level that maximizes prediction accuracy without exceeding your expected waiting time, you must have an estimate of the processing time of SIFTER given the input protein family for each truncation level. We provide this estimate on the download tab of this website to guide you in choosing the truncation level that well balances this trade-off.
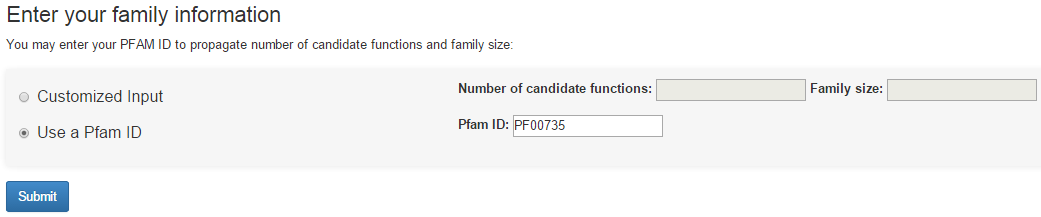
We use a predictive model trained on existing SIFTER data to estimate the processing time of SIFTER. Just enter the PFam ID of that family or provide the number of candidate molecular functions and family size of that family and press submit.
Here is an example that searches for the protein family with PFam ID PF00735, which has 11 candidate molecular functions and family size 2609.
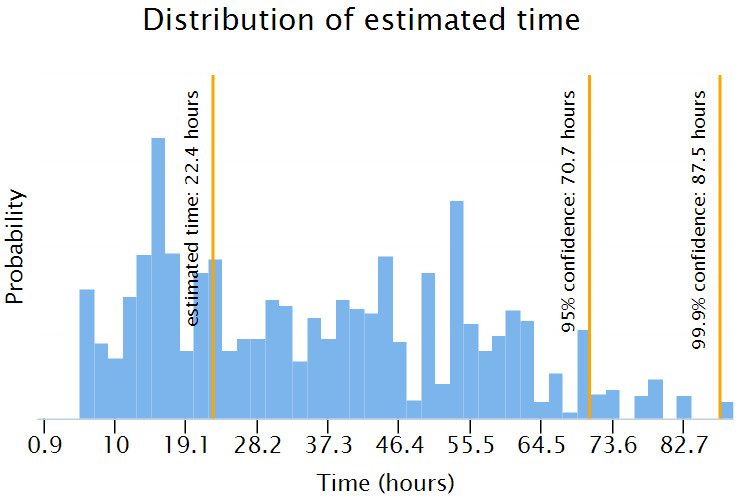
When you press submit, the web page displays a table of estimated times. Each row contains the truncation level, the estimated time in hours and in user-friendly units, and the 95% and 99.9% confidence upper bounds for the estimated time, also in the same units. (95% confidence upper bound means that the actual time will be less than that bound with probability 0.95).
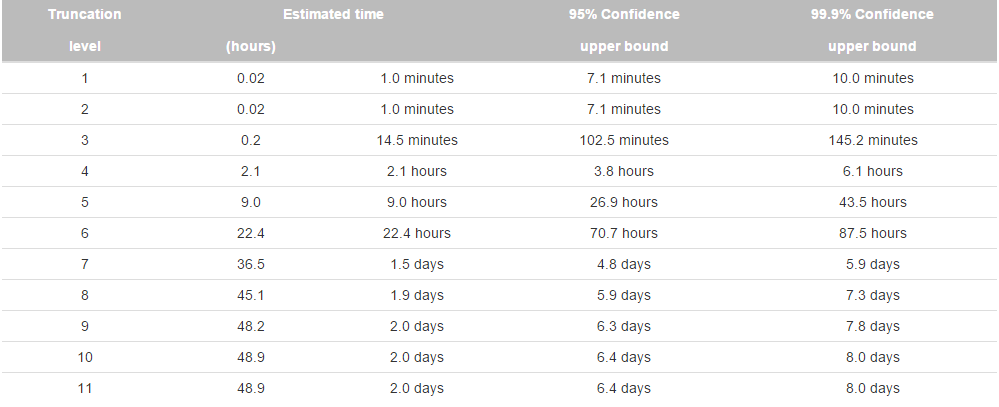
When your mouse hovers over one of the rows, the web page highlights that row and displays the corresponding relative probability distribution of the estimated time for that row.
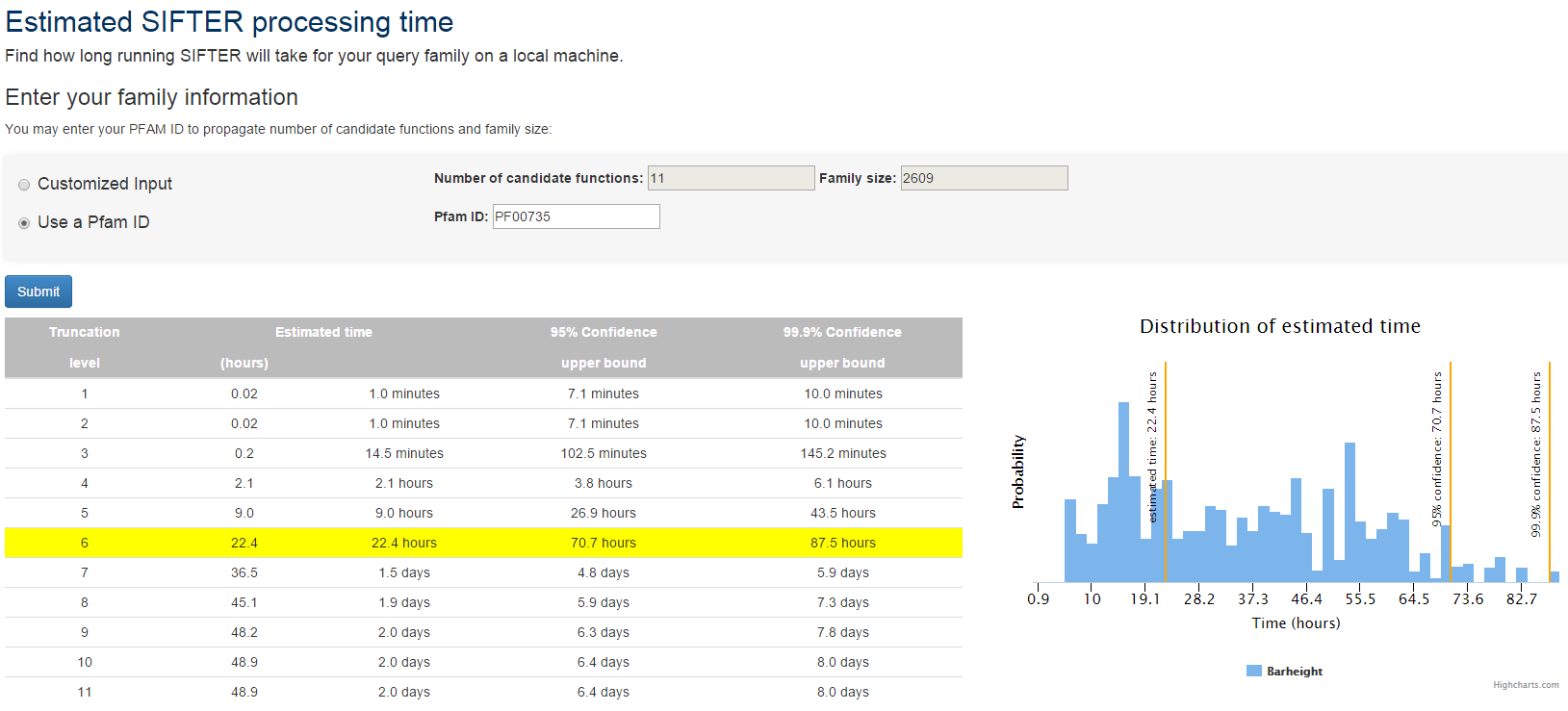
Here is the distribution of estimated time for truncation level 6. The vertical lines on the distribution indicate the estimated time (22.4 hours) and 95% and 99.9% confidence upper bounds (70.7 hours and 87.5 hours).